

この記事でわかること
-
Elasticsearch・Splunkの実践的な使い分け術と導入成功パターン
-
エンタープライズツール浸透のための4段階アプローチ
-
「インフラ知識ゼロ」から始めるログ分析基盤の習得法
Elasticsearch(※1)やSplunk(※2)といったログ分析(※3)基盤、Kubernetes(※4)などのコンテナオーケストレーションツールは、適切に活用すれば業務効率を大幅に向上させる強力なツールです。しかし、多機能で高価なこれらのツールを現場で本当に使いこなすには、技術的な知識だけでなく、組織への浸透戦略も必要になります。
そんな中、Web開発エンジニアからスタートし、現在はこれらのツールを現場で使い倒すスペシャリストとして活躍しているのが、株式会社エーピーコミュニケーションズの長谷川脩氏です。
本記事では、長谷川氏へのインタビューを通じて、高機能なエンタープライズツールを現場で使いこなし、確実に成果を出すための実践的な知見をお伝えします。
※1 Elasticsearch:検索・分析エンジン。大量のデータをリアルタイムで検索・分析できるオープンソースツール。KibanaやLogstashなどと組み合わせて使用することが多い。
※2 Splunk:企業向けログ管理・分析プラットフォーム。サーバーログやアプリケーションデータの収集・可視化・分析を行う有償ツール
※3 ログ分析:データ分析と混同されるが、データ分析はより広義である(データサイエンスも含める)ため、本記事ではログ分析で統一する。
※4 Kubernetes:コンテナオーケストレーションプラットフォーム。アプリケーションのデプロイ・管理・スケーリングを自動化

長谷川 脩
株式会社エーピーコミュニケーションズ
クラウド事業部クラウドエンジニアリング部 プロフェッショナル職エンジニア
2014年にエーピーコミュニケーションズに入社し、Web UI開発やアプリ開発を担当。翌年から顧客常駐として社内ツールの開発を手がけ、2017年にElasticsearchとの出会いをきっかけにログ分析基盤の世界に足を踏み入れる。2021年からはSplunkの活用も開始し、同年に社内大学「APアカデミー」の講師としても活動を開始。現在はデータ分析による業務効率化や開発チーム立ち上げ支援に従事しながら、年間約100講座を実施する社内大学「APアカデミー」にて講師としても知見を展開している。
【関連URL】:https://connpass.com/user/o_hasegawa
株式会社エーピーコミュニケーションズ
1995年11月創業。ITインフラ自動化のプロフェッショナルとして、Azure Kubernetes ServiceやAnsibleなどを用いたクラウドネイティブ環境の内製化・自動化支援やシステムインテグレーションを手がける。お客様の課題解決と共に、エンジニアが熱狂できるキャリアパスの創出にも積極的に取り組んでいる。
【URL】:株式会社エーピーコミュニケーションズ | AP Communications (APC)
目次
データ分析が未経験でも、Elasticsearch・Splunkをゼロから学んで活用できる

まず、長谷川さんの現在のお仕事について教えてください。

現在は顧客常駐先で開発支援の仕事をしており、データ分析による業務効率化と、顧客内での開発チーム立ち上げをサポートしています。社内では研修講師として、Elasticsearch、Splunk、Kubernetesなどの知見を展開する活動も行っています。
Web開発からインフラ系ツールまで幅広く経験されていますが、キャリアの変遷で印象的な出来事があれば教えてください。
前職では運用保守がメインで、新規開発の経験が少なかったんです。趣味でホームページを作っていたこともあり、Web開発をやりたくて転職しました。
ただ、開発部署に入ると、iPhoneアプリやVR開発ができるような、技術力の高い方々がいる環境で、最初はついていくのに苦労しました。でも、諦めずに取り組み続けたことで、現在のスキルベースを築けたと思います。
ElasticsearchやSplunkを使い始めたきっかけは何だったのでしょうか?
実は、特に明確な課題があって始めたわけではないんです。2017年当時、私はデータ分析という概念すら知らなくて、データの格納先といえばリレーショナルデータベースしか知りませんでした。
ある時、顧客先でElasticsearchを使える環境があるので活用してみませんかという提案があり、チーム内で使える人がいなかったため、私が担当することになりました。最初は試験的な運用から始まったという感じです。
試験的な運用から始まって、どのような価値を見出されたのでしょうか?
運用作業における手動作業の割合を見ることが重要だと気づきました。手動でやっている作業は、アプリケーション開発・保守コストと人的コストの両方がかかっています。
例えば、毎日決まった時間にログを確認して、特定の条件が発生したらエスカレーションするような作業を、Splunkのアラート機能で自動化できます。これにより開発保守コストと人的コストの両方を削減できるので、そこに大きな価値を感じました。
Splunkの利用率が20倍に!? 現場に浸透させる4段階のアプローチ
ElasticsearchとSplunkの特徴や使い分けについて教えてください。
簡潔に言うと、Elasticsearchはコスト重視でデータ構造をしっかり定義したいとき、コードを書ける人がチームにいるときに向いています。基本機能は無償で使えるのも大きなメリットです。
Splunkは逆に、予算に余裕があって早期立ち上げを重視するとき、ログのフォーマットが不揃いで事前定義が困難なとき、初心者を含む大人数での展開を考えているときに適しています。有償ツールなので、ベンダーサポートや研修が充実している点も強みです。

Splunk歴3年半でチーム内の利用率を20倍以上に増やされたそうですが、どのような取り組みをされたのでしょうか?
段階的にアプローチしました。まず絶対にやってはいけないのは、「Splunkにデータを入れたから皆さん使ってください」という一方的な告知です。これでは絶対に使われません。私が実践したのは4段階のアプローチです。
アプローチについて、具体的に教えてください。
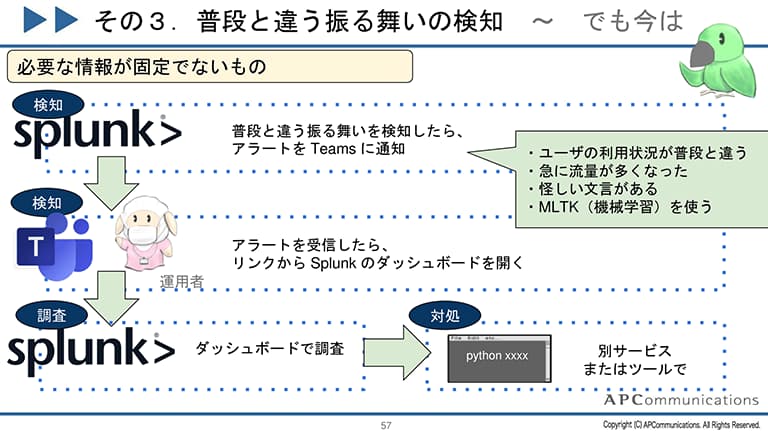
第1段階では、とにかく自ら使い倒して「実際の運用データ」を取得し、運用作業に直結するダッシュボードを作成します。
第2段階は「実演アプローチ」です。これは、実際の運用作業中にメンバーの作業に割り込んで「その作業、Splunkならこうできますよ」と実際に画面を見せながら実演することです。スーパーの試食販売のように、実際に体験してもらうわけです。最初はスルーされることも多いですが、リンク共有が広がって徐々に認知が進みます。
第3段階では、既存の手順書に「Splunkでの確認」を並行で追記して、慣れてもらいます。質問には必ず答えて、SPL(Splunkの検索クエリ)の雛形を提示することも重要です。
最終的に、メンバーからデータ投入依頼が来るようになる、そしてダッシュボードをチームメンバーが自発的に作るようになれば成功です。現在では、私が関わらなくてもチーム内でデータ投入やIaC(Infrastructure as Code)での運用が標準化されています。
段階的なアプローチで着実に浸透させていったんですね。実演アプローチは効果的だと思います。
「Elasticsearchは難しい」のはなぜ? データ投入の壁を生成AIで突破する
Elasticsearchについて「難しい」という声をよく聞きますが、実際の課題と解決策を教えてください。
Elasticsearchは無償で使える反面、技術的な敷居が高い部分があります。最大の難所はデータ投入です。Splunkは後から整形(検索時に必要な項目だけ抽出)するのに対して、Elasticsearchは先にデータ定義をして整形する必要があります。データウェアハウスに近い考え方ですね。
特にLogstash(※5)というデータ投入ツールが厄介で、デバッグがやりにくい。JSON(※6)や正規表現(※7)の知識も必要になります。
※5 Logstash:Elasticsearchエコシステムのデータ収集・変換ツール
※6 JSON:JavaScript Object Notationの略。データ交換フォーマットの一種
※7 正規表現:文字列のパターンを表現するための記法

その課題をどのように解決されましたか?
現在では生成AIを活用することで、この問題を大幅に軽減できます。Logstashの設定ファイルを生成AIに作ってもらい、トライアンドエラーで調整していく方法が非常に有効です。
昔は一から勉強する必要がありましたが、今は「こういうデータがあって、これをElasticsearchに投入したいのですが、Logstashの設定はどうすればいいですか」と生成AIに相談できます。完璧ではありませんが、良いたたき台を作ってくれるので、学習コストを大幅に削減できます。
Kubernetesも同様に生成AIを活用されたそうですが、どのようなメリットを感じていますか?
Kubernetesの場合、設定ファイルに基づく一括デプロイで再現性と効率性が格段に向上しました。従来のオンプレミス環境では、サーバーのスペックやライブラリをホストごとに個別管理する必要がありましたが、Dockerfileなどの設定ファイルをしっかり定義すれば、インフラの詳細知識がなくても環境構築ができるようになります。
ただし、従来の「その場しのぎの修正」ができないというデメリットもあります。コンテナの不変性の原則により、本番環境に直接ログインして手動でファイルを修正するといった対応ができません。これは最初は戸惑いましたが、結果的により堅牢なシステム運用につながっています。
ログ分析基盤を導入して成果を出すために、最初の3ヶ月で重要なことは何でしょうか?
ElasticsearchやSplunkで共通する3ヶ月のロードマップをお話しします。1ヶ月目は、ミニマム環境で現場のデータを投入し、運用に直結する基礎ダッシュボードを作成して、まず自分が徹底的に使い込みます。
2ヶ月目は実演アプローチを開始します。少量データでの価値提示と要望収集を行い、改善サイクルを確立します。SplunkはUniversal Forwarder(※8)でリアルタイム化を早期実装、ElasticsearchはLogstash設定を生成AIで下書きして検証を進めます。
3ヶ月目は実データの継続流入を前提にダッシュボード拡充とアラート試行を行います。また、手順書への組み込みも行いながら、インフラの本格化も検討します。専門家とスケール設計、容量・性能・可用性をレビューするのがこの段階です。
※8 Universal Forwarder:Splunk専用の軽量ログ収集ツール
Web開発経験者が「ログ分析で有利」な3つの理由
Web開発エンジニアがこれらのツールを習得する上で効果的な学習方法は何でしょうか?
基本的には実際に触ることに尽きます。読書で覚えるよりも、まず手を動かすことです。
Kubernetesを始めた時がまさにそうで、マニフェストファイルの作成から原理まで一から勉強していたら相当時間がかかると感じました。そこで生成AIに「こういう設定ファイルがあって、これをコンテナ化するとしたらどう変わりますか」と相談しながら、トライアンドエラーで進めました。
チームメンバーのスキルレベルが異なる場合の知識共有はどうされていますか?
実演を通して具体例で教えることが大切です。「このデータが欲しいときはこういうSplunkの関数を使う」「検索でアスタリスクを使うとワイルドカードになる」といった実例を踏まえて伝えます。
また、図解が重要です。Logstash→Elasticsearch→Kibana(※9)といったデータフローを可視化することで、理解度が格段に上がります。研修でも「図解が分かりやすかった」「実際のデータを使ってのハンズオンだったので理解しやすかった」という反響を多くいただいています。
※9 Kibana:Elasticsearchのデータ可視化ツール
ElasticsearchやSplunkの習得において、Web開発エンジニアならではのアドバンテージはありますか?
Web開発エンジニアには、ログ分析において3つの大きなアドバンテージがあります。
1つ目は、UI開発の経験があることです。ダッシュボードの配置や見せ方の設計ができ、「必要なグラフだけをシンプルに配置する」といったWeb開発の常識が活かせます。
2つ目は、SQLの知見です。複雑な検索クエリの組み立て、複数条件の組み合わせ、階層構造の理解などで威力を発揮します。
3つ目は、正規表現やJSONの経験です。詳細機能を使いこなして、検索の自動化やマクロ機能の活用につながります。
Web開発の経験が直接活かせるというのは心強いですね。
「言われた通りのログを入れても使われない」現場の真実と要件定義の成功法
ログ分析基盤の技術選定において、表面的な要件と「本当の要件」にギャップが生じるケースはありますか?
よくあります。顧客から「このログを入れて検索できるようにしてほしい」と言われて、その通りにシステムを作っても、結局使ってもらえないケースです。最終的には従来通りUNIXのログを手動で確認する、ということになりがちです。
そういうときは、ロジカルシンキングの基本に戻って、相手が本当に必要としているものを運用作業の実態から把握する必要があります。具体的には、実際の運用作業を観察して「この人はこういう検索をしているということは、こういう情報が欲しいんだな」「このタイミングでこの確認をするということは、こういう判断材料が必要なんだな」というところを把握することが重要です。
その「観察」というのは、具体的にはどのようなアクションを指すのでしょうか?
実際の運用作業に同席して、どのコマンドを実行しているか、どのログファイルを開いているか、どんな検索条件を使っているかを見ることです。また、TeamsやSlackなどのチャットを確認して「こういう作業をしている」「時間がかかってそうだな」というパターンを発見したら、それをダッシュボードで解決できないか検討します。
要は、手順書に書いてある作業と実際の作業にギャップがある場合が多いので、実際の作業フローを把握することが大切です。
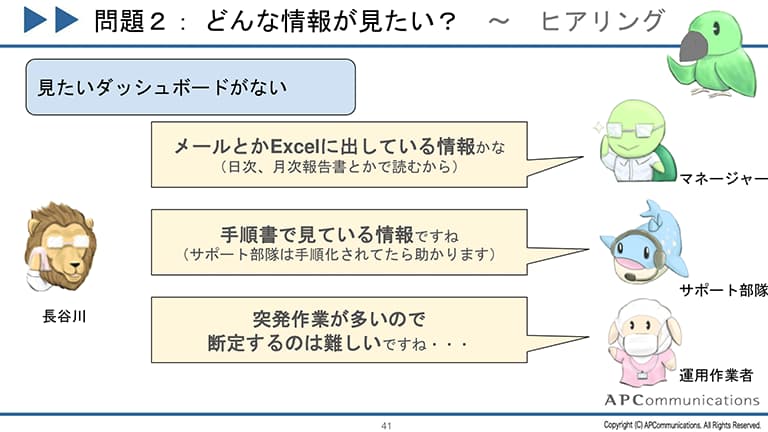
要件定義で必ず確認すべきポイントはありますか?
コスト以外では、ログの種類と組織のスキルレベルが重要です。
フォーマットが不確定なログが多いなら、後から整形できるSplunkが便利です。しっかりした定義のログが中心なら、Elasticsearchでデータ構造を事前定義した方が、設計書の代わりにもなって後の管理がしっかりできます。
また、コード開発経験(特にPython)やJSONの知識がある人が社内にいればElasticsearch優位、初学者が多く短期で可視化したいならSplunk優位という判断軸もあります。なお、正規表現はSplunkのクエリ(SPL)組み立てに有効ですが必須ではなく、SQLの知見はどちらのツールでも活用できます。
高額なツールと安価なツールの選択において、どのような判断基準をお持ちですか?
研修で使っているチェックリストがあるのですが、主要な判断軸は以下の通りです。まず、コスト制約が厳しくデータ構造を明確に定義でき、開発者リソースがあるならElasticsearchです。
一方、早期立ち上げを重視し、ログフォーマットが不揃いで、初心者を含む大人数での展開を考えているならSplunkが適しています。また、数値中心の軽量な時系列監視にはPrometheusも選択肢になります。

ただし、これは一般論で、実際は組織の文化や予算、メンバーのスキルレベルを総合的に判断する必要があります。現場からは必ずコスト削減の要望が出るので、比較検討は避けて通れません。
【参考動画】:「8a1」APC勉強会#42:事例で学ぶSplunkの活用方法<
AI時代のログ分析ー属人化の解消で「業務負荷3分の1」を実現
生成AIとSplunkを組み合わせた活用方法について教えてください。
生成AIの活用には大きく2つの側面があります。
まず、SPL(Splunkの検索言語)クエリの生成支援です。利用者によってスキルレベルが違うので、「こういう検索をしたい」と生成AIに依頼すれば、適切なクエリを作ってくれます。これにより、技術的なリテラシーが異なるメンバーでも同じベースに立てるようになりました。
もう一つは、機械学習の前処理で発見した法則をSplunkのアラートに組み込むことです。データクリーニングの工程で「この条件の時は要注意」という法則を見つけて、それを自動検知に活用しています。
ログ分析における自動化の効果はどの程度でしたか?
従来の方法に比べて、メンバーの負荷が約3分の1に減ったと思います。何より大きいのは属人化の解消です。従来の「これは職人じゃないとできない」「このログの怪しい箇所は経験者にしか分からない」という状況を、自動化によって解消できました。
興味深いことに、機械学習を試行する過程で副産物として発見した法則が非常に有効でした。詳細は機密情報に関わるためお伝えできませんが、データの前処理で見つけたパターンをアラート条件に組み込むことで、大幅な効率化を実現できています。
予想外の成果が得られたということですね。制約や課題はありますか?
最大の制約は機密情報の取り扱いです。生成AIを使う場合、企業契約でデータの学習利用をしない設定は可能ですが、顧客によっては個人情報を外部に出すこと自体を禁止している場合もあります。
契約やポリシーに依存する部分なので、その制約の中での活用になります。ただ、活用できる環境では確実に効果が出るので、可能な範囲での積極的な活用をお勧めします。
ドキュメントより実践。ログ分析基盤を最速で身につける秘訣
Web開発からインフラ系のツールを扱うようになって、何か気づいたことはありますか?
私は基本的に開発の分野に特化していますが、ElasticsearchやSplunkではそのスキルがそのまま活かせるんです。先ほども一部お伝えしましたが、UI設計、クエリ組み立て、データ構造の理解など、Web開発で培った経験が直接役立つので、インフラの現場でも価値を提供できています。
特に、開発経験の無いインフラのメンバーへの技術的知見のサポートやレクチャーもできるので、チーム全体の底上げにも貢献できていると感じます。
開発経験が思わぬところで活かされているんですね。長谷川さんは、SplunkやElasticsearchの研修講師もされているそうですが、どんな効果を感じていますか?
社内との繋がりができたのが一番大きいです。長期間、顧客先に常駐していると「自分はどこの会社の人間なんだろう」という疑問を抱くことがあります。研修や登壇ができることで、その課題が解消されて、会社への帰属意識も高まりました。
また、知見を整理して人に伝える過程で、自分自身の理解も深まります。受講者からの質問で新しい気づきを得ることも多いです。
これから、ElasticsearchやSplunkなどのツールを学びたいエンジニアへのアドバイスをお願いします。
繰り返しになりますが、まずは実際のデータを入れて触って動かしてみることが一番大事です。昔、ドラゴンクエストで「武器や防具は装備しないと意味がないぞ」というセリフがありましたが、それと同じで「データ分析基盤はデータを入れないと意味がないぞ」ということです。
最初は難しそうに見えるし、ドキュメントも英語なので躊躇する方も多いと思いますが、まず触ってみることです。身近なデータを使えば理解も反応も良くなります。そして、諦めずに新しい領域にチャレンジし続けることが、エンジニアとしての成長と価値創出につながると思います。
ライター
