

この記事でわかること
-
なぜ今、エンジニアのナレッジ管理に「Obsidian × Cursor」が最適解なのか
-
AI Agentに守らせる「タグ付け」「フォルダ構成」の具体的ルールと設定
-
個人の「知的資産」をチーム開発やGitHubでのナレッジ共有に活かすワークフロー
生成AIの進化により、エンジニアの「書く」という行為の意味が変わりつつあります。 メモやドキュメントは、単なる備忘録から、AIという強力なパートナーを動かすための「命令セット」へと進化しました。
今回は、エンジニアとしての業務の傍ら、ノートアプリ「Obsidian(※1)」とAIを組み合わせた革新的な活用術を発信し、Note記事「Obsidianの一元管理を実現する」でも話題を呼んだ山口大陽(松濤Vimmer)氏にインタビュー。
そのノウハウを体系化した著書『Obsidian×AI クリエイター&エンジニアの知的生産性を高める徹底活用術』も出版された同氏に、クラウドファーストなNotionなどの既存ツールも併用しながら、なぜあえてローカルファーストなObsidianを選ぶのか。そして、AIエディタ「Cursor」と連携させることで生まれる「開発効率の爆発的向上」について、具体的な設定やワークフローを教えていただきました。
※1 Obsidian(オブシディアン) ノート同士をリンクで結び付けて知識のネットワークを作ることができるノートアプリ。作成したデータはクラウドではなくローカル環境(PC内)にMarkdown形式のテキストファイルとして保存されるため、動作が高速でオフラインでも利用可能。特定のサービスに依存せず半永久的にデータを管理できる点が、エンジニアや研究者から高く評価されている。
山口大陽(松濤Vimmer)
株式会社サイバーエージェントでのエンジニア業務の傍ら、「松濤Vimmer」としてObsidianやAI活用術を精力的に発信。Note記事「Obsidianの一元管理を実現する」がエンジニア界隈で大きな反響を呼ぶ。開発したObsidianプラグインは2,000ダウンロードを突破。
【X(旧Twitter)】:https://x.com/shotovim?s=20

Obsidian×AI クリエイター&エンジニアの知的生産性を高める徹底活用術
出版社:マイナビ出版 著者:山口大陽
目次
Obsidianのメモが、自分専用のAIを育てる“知的資産”に変わる

山口さんは「松濤Vimmer」としてObsidianやAI活用に関する情報を精力的に発信され、Note記事はエンジニア界隈で非常に話題になりました。改めて、現在の活動スタイルに至った背景をお聞かせいただけますか?

もともとは、純粋にAI技術の内容をDeep Dive(深掘り)するような発信を考えていたんです。ただ、AI技術そのものの解説者はすでに多く存在していました。
そこで、何か別の軸と組み合わせた発信ができないかと模索していた時に、ObsidianがAIとの親和性が非常に高いことに気づいたんです。「これだ」と思い、ObsidianとAIを掛け合わせた活用術の発信に切り替えました。
今回のテーマでもある「メモはエンジニアの知的資産である」という考え方は非常に示唆に富んでいると感じます。これまでの「メモ」の概念と何が違うのでしょうか?
これまでのメモは、あくまで「人間(未来の自分や他者)が読むため」のものでした。しかし、生成AIが登場したことで、ドキュメントには「AIを最大限活用するためのコンテキスト(文脈)として残す」という極めて重要な役割が加わりました。
人間だけでなく、AIに読ませることを前提にするということですね。
その通りです。正確かつ最新の情報をストック情報として資産化しておくことが、結果としてAIのアウトプット品質に直結します。つまり、エンジニアは「今の自分の備忘録」としてだけでなく、「未来のAIに的確な指示を出すためのデータベース」を作るというマインドセットを持つ必要があります。

Notion派のエンジニアが「Obsidian」も活用する合理的な理由
現在、多くの企業やエンジニアがドキュメント管理にNotionを使用しています。山口さんもNotionを使われているかと思いますが、なぜ個人の管理にはあえてローカルファーストのObsidianを選ばれているのでしょうか?
まず大前提として、私はNotionを否定しているわけではありません。チームでのコラボレーションやデータベース機能において、Notionは非常に優秀なツールです。しかし、個人の思考整理や、特に「AI活用」という視点に立った時、Obsidianのようなローカル型のツールには決定的なアドバンテージがあります。
具体的にはどのようなアドバンテージでしょうか?
最大の理由は 「ローカルファイルへのアクセス速度」と「AIモデル選択の自由度」 です。NotionにもNotion AIがありますが、Claude CodeやCodex、そしてCursorといった最新のAIエディタは、ローカルファイルへのアクセスが圧倒的に速いんです。
MCP(Model Context Protocol)などを使えばクラウド上のファイルも参照できますが、やはりローカル参照の爆速感には及びません。
たしかに、エンジニアにとって数秒のレスポンスの遅れはストレスになりますし、思考のノイズになりますよね。そもそも、Obsidianはどのような仕組みでデータを管理しているのでしょうか?
Obsidianでは、ノートや関連ファイルを保存する基本的な単位を 「保管庫(Vault)」 と呼びます。これは特殊なデータベースではなく、PCのローカル上にある「通常のフォルダ」そのものです。この中にMarkdown形式のテキストファイルや画像がそのまま保存されています。
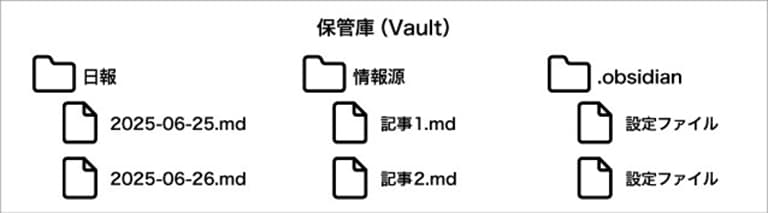
データの実体が自分のPC内にあるため、 AIに「この保管庫(フォルダ)を読み込んで」と指示するだけで、即座にコンテキストとして渡すことができます。
また、クラウドサービスに依存しないため、その時々で最も賢い最新のAIモデルを自由に選んで使えるのも大きなメリットです。クラウドサービスのAI機能のアップデートを待つ必要がありません。
「 自分のデータを特定のプラットフォームにロックインさせない 」という意味でも、エンジニアらしい合理的な選択だと感じます。
それに、Obsidianはエンジニア好みのカスタマイズ性が高いのも魅力です。私は活動名の通りVim愛好家なのですが、Obsidianには標準で 「Vimモード」 が備わっています。
マウス操作なしでキーボードだけで思考を記述できる快感は、一度味わうと離れられません。チームワークはNotion、個人の脳内拡張はObsidianと、役割を明確に分けるのが最適解だと考えています。
開発効率を最大化する「Obsidian in Cursor」実践セットアップ
ここからは今回のメインテーマである「Obsidian in Cursor」について深掘りさせてください。通常、CursorはコーディングのためのAIエディタですが、そこでメモアプリであるObsidianのデータを開くことで、どのようなメリットが生まれるのでしょうか?
開発効率が劇的に変わります。エンジニアにとって、コーディング中にブラウザで仕様書を探したり、別のメモアプリに切り替えたりする「コンテキストスイッチ」は、集中力を削ぐ最大の要因です。
Cursor内でObsidianを開くことで、開発、ドキュメントの検索、仕様の確認、そしてAIへの指示出しが、すべて一つのウィンドウ内で完結します。気が散りやすいタイプの私にとって、画面遷移が発生しない環境は「ゾーン状態」を維持するのに非常に効果的でした。
実際にCursorとObsidianを連携させる際、フォルダ構成やルール設定で工夫されている点はありますか?
AIに正確な情報を参照させるために、明確なフォルダ設計を行っています。具体的には、「read-only(読み取り専用)」フォルダを作り、NotionからAPIで取得した公式ドキュメントや議事録などを格納します。AIには「このフォルダは参照専用で、絶対に編集してはいけない」というルールを徹底させます。
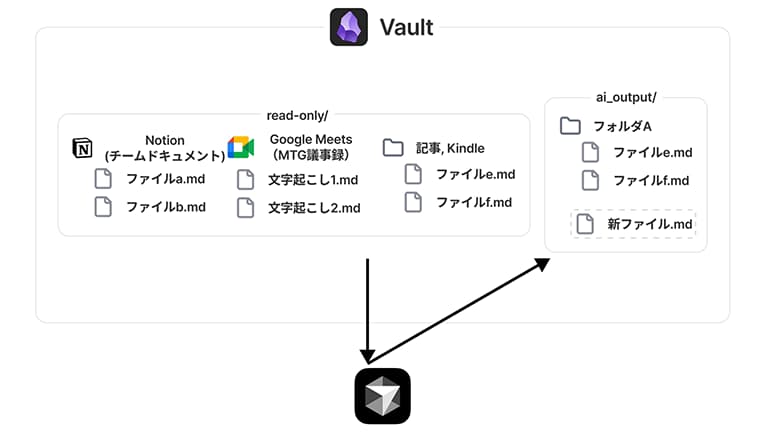
一方で、AIが生成したアウトプットは「ai-output」フォルダに格納します。こうして「信頼できる一次情報」と「AIの生成物」を明確に分けることで、情報の正確性を担保しています。 さらに、CursorのAI Agentには「ルールファイル(.mdc)」を読み込ませて、運用の自動化を行っています。
AIに対する指示書のようなものですね。具体的にはどのようなルールを設定されているのでしょうか?
例えば、以下のようなルールファイルを作成して、AIに守らせています。

これに加えて、タグ付けのルールも厳格に決めています。「タグは最大5個まで」「すべて小文字の単数形で統一(notesではなくnote)」といったルールをAIに守らせることで、タグがカオスになるのを防ぎ、検索性を維持しています。 また、テクニカルライティングの観点からも、AI特有の「革新的」「画期的」といった誇張表現や、過剰な絵文字の使用を禁止し、textlint(文章校正ツール)も実行させて品質を管理しています。
インプットからアウトプットへ。リポジトリ解析とLINE活用ワークフロー
インプットだけでなく、アウトプットにおける具体的なワークフローについても教えてください。普段、どのように情報を収集し、それをどうやって資料作成などに活かしているのでしょうか?
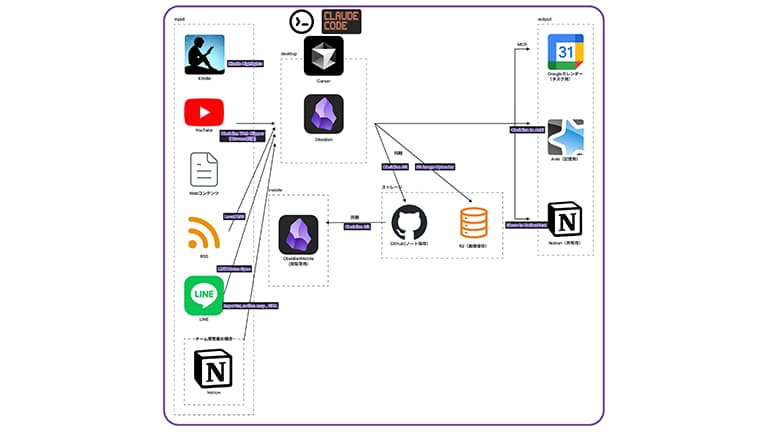
私のワークフローの入り口は、場所を選ばずメモができる環境を作ることです。外出先では自作した「LINE Notes Sync」というプラグインを使って、LINEから自分宛にメモを送ります。PC作業中は「Thino」というX(旧Twitter)ライクにつぶやけるプラグインや、デイリーノートにひたすら書き込みます。
まずは、あらゆる思考の断片をObsidianに集約するわけですね。
アウトプットの段階では、それらのメモや、対象となるGitHubリポジトリのコードをCursorに読み込ませます。 「このコードと、過去のこのメモを参考にして、仕様書のたたき台を作って」と指示を出し、まずはドラフトを作成させます。
プレゼン資料やスライド作成も以前は自動生成を試みましたが、どうしてもデザインの微調整や、伝えたいニュアンスのズレが生じるので、現在は構成案やテキストの生成までをAIに任せ、最終的な仕上げは自分で行っています。
リポジトリのコード自体をAIに理解させているので、技術的な仕様の解説や、コードリーディングの補助としても強力そうですね。
おっしゃる通りです。ドキュメントだけでなくコードもコンテキストとして渡すことで、AIの回答精度は格段に上がります。これは非エンジニアの方がコードベースを理解する際にも非常に有効な手法だと思います。
GitHubでつなぐ。個人の知をチームのナレッジエコシステムへ
ここまで個人の活用術を伺ってきましたが、組織での活用についてもお聞きしたいです。Obsidianで構築したシステムを、チームのナレッジマネジメントに還元することは可能でしょうか?
可能ですし、むしろ推奨したいですね。私が実践しているのは、GitHubを中心としたナレッジエコシステムの構築です。 チームではNotion、Slack、Gmailなど複数のツールを使いますが、それぞれのツールからAPI経由でデータを取得し、GitHub Actionsを使って定期的にMarkdownファイルとしてGitHubリポジトリに集約します。
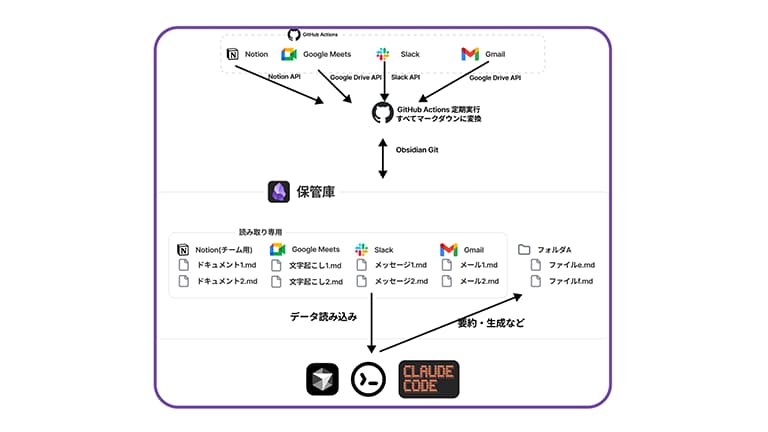
これにより、チームメンバーは使い慣れたNotionやSlackを使い続けられます。一方で、裏側ではすべての情報がテキストデータとして一元化されているため、それをObsidianで読み込めば、個人のAI活用リソースとして利用できます。
「チームのツールを無理に変えることなく、個人の生産性を最大化する」という意味で、非常に現実的な解だと思います。
これから「Obsidian × Cursor」を始めたいエンジニアに向けて、最初の一歩としてのアドバイスをお願いします。
まずは、Obsidianに「Obsidian Git」というプラグインを導入することをおすすめします。これさえ入れれば、GitHubとの同期を自動化できるので、バックアップやバージョン管理の手間がなくなります。エンジニアであればGitの概念には慣れているはずなので、導入のハードルは低いはずです。
先ほどのお話にあった「read-only」フォルダの作成も重要ですね。
そうですね。APIで取得した外部データや、AIに参照させるだけの一次情報は、誤って編集しないように隔離して保護する。こうして「情報の正確性」を担保した領域を作ることで、AIがハルシネーション(嘘)を起こすリスクを減らし、信頼できるアシスタントとして育てることができます。
あとは、使いながら自分好みのプラグインを少しずつ足していけば、挫折せずに続けられると思いますよ。
最後に、AIの進化によってエンジニアに求められるスキルはどう変わっていくとお考えでしょうか?
これまでは「知識の量」が価値でしたが、それはAIが代替してくれます。これからは 「設計」や「技術選定」といった0→1の部分 が重要になります。この初期設計こそが、AIに渡す「コンテキスト」の質を決定づけるからです。 つまり、「書く」「残す」という行為自体が、自分専用のAIアシスタントを教育するプログラミングそのものになります。
そうして育てた「知的資産」を武器に、より本質的な課題解決に時間を割くこと。それがこれからのエンジニアの生存戦略ではないでしょうか。ぜひ、ObsidianとAIを組み合わせて、自分だけの最強のナレッジベースを作ってみてください。
ライター
