

この記事でわかること
-
生成AI特有の「確率的生成」を理解することで得られる、実装とデバッグのスピードアップ
-
「もっともらしいウソ」が起きるメカニズムの理解と、システムアーキテクチャによる対策
-
非技術者(経営層・クライアント)に対し、AIの限界を論理的に説明するためのロジック
生成AIのAPIを叩けば、誰でも簡単にAIアプリが作れる時代になりました。しかし、開発現場では「プロンプトをどう調整してもハルシネーションが直らない」「コストが想定外に膨れ上がる」「特定の入力で挙動が安定しない」といった、中身が見えないことによる課題に直面するエンジニアが増えています。
「AIは高速で『思考』しているのではなく、確率を『計算』しているに過ぎない」 この視点を持つことで、ブラックボックス化しがちな生成AIの裏側は、エンジニアが制御可能な対象へと変わります。
今回は、元デンソーのソフトウェアエンジニアであり、現在は数多くの技術書を手掛けるITライターの立山秀利氏にお話を伺いました。立山氏の著書『生成AI「思考」の裏側』の内容も交えながら、エンジニアだからこそ知っておくべき「生成AIの論理」と、それを実務にどう活かすかについて深掘りします。

生成AI「思考」の裏側 なぜ賢いのか? なぜ間違うのか?
出版社:日経BP 著者:立山 秀利
立山 秀利
ITライター。筑波大学卒業後、株式会社デンソーでカーナビゲーションのソフトウェア開発に携わる。退社後、Webプロデュース業を経て、フリーライターとして独立。現在はシステムやネットワーク、Microsoft Officeを中心に執筆中。主な著書に『Excel VBAのプログラミングのツボとコツがゼッタイにわかる本』(秀和システム)、『入門者のExcel VBA』(講談社ブルーバックス)、『ディープラーニングAIはどのように学習し、推論しているのか』(日経BP)など多数。
【X(旧Twitter)】:https://x.com/HTateyama?s=20
目次
なぜエンジニアは今、Transformerの仕組みを学ぶべきなのか

立山さんは、ITライターとして多くの技術書を執筆されていますが、キャリアのスタートはソフトウェアエンジニアだったそうですね。 多くの「生成AI解説書」がある中で、今回あえて技術的な「中身」に踏み込んだ書籍を執筆されたのは、ご自身のエンジニア経験が影響しているのでしょうか?

そうですね。私自身、かつてはC言語などでロジックをガリガリ書いていた人間なので、エンジニアが抱く「中身がわからないものが動いている気持ち悪さ」がよくわかるんです。 今の生成AIは非常に便利ですが、エンジニアにとってブラックボックスな部分が多い。
「とにかく動けばいい」と割り切れない、エンジニアならではのジレンマがあるわけですね。
そのため、「AIはなんだか怖い」と漠然と不安を感じたり、逆に「AIなら魔法のようになんでもできる」と過信してしまったりしがちです。 そうした誤解を解くためには、最低限の「原理原則」を理解してもらう必要があると考えました。
できるだけ数式は使わずにブラックボックスの中身をしっかり見せることで、エンジニアの方々が「ああ、こういう理屈で動いているのか」と納得し、安心して使いこなせるようになることを目指しました。
その「中身」の核となる技術が「Transformer」ですね。
はい。今の生成AIブームの火付け役となったのが、このTransformerというアーキテクチャです。 ただ、エンジニアが特に知っておくべきなのは、Transformerの中身が巨大な「ニューラルネットワーク」の塊であり、従来のプログラムとは根本的に作りが違うという点です。
従来のプログラムは、エンジニアが「if A then B」とロジックをコードで記述しましたが、ニューラルネットワークは、学習によって調整された「膨大な数値(パラメータ)の集合体」で動いています。つまり、どこにも明示的なロジックが書かれていないんです。
なるほど。AIを使わない開発経験が長いエンジニアほど、ロジックが追えないものを怖いと感じるような気がします。
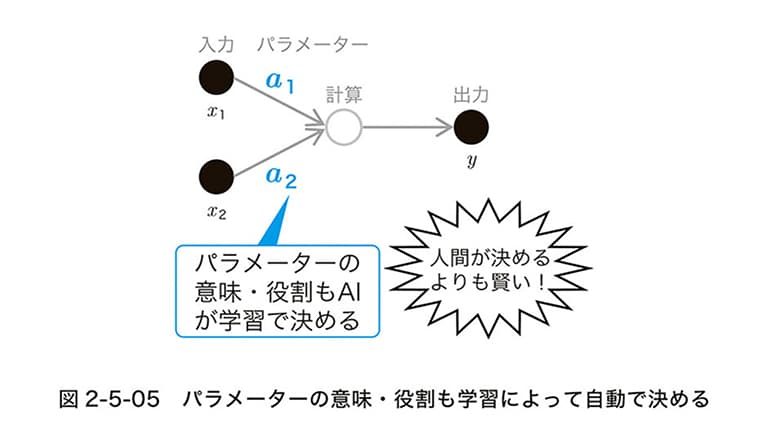
一番のギャップは、「パラメータの意味や役割を、人間ではなくAI自身が決める」という点だと思います。 AIがなかった頃の開発では、例えば売上予測プログラムを作るなら、「客数」や「単価」といった変数を人間が定義し、計算式を設計します。すべて人間がコントロール下に置いていました。
仕様書に変数を定義して、ロジックを組むのが当たり前ですね。
ところが、ディープラーニングの世界は全く違います。人間が決めるのはネットワークの構造だけで、内部にある数億、数千億というパラメータが具体的に何を意味するのかは、AIが学習データから勝手に決定します。
あるパラメータが「文法」を司っているのか、「言葉のポジティブなニュアンス」を表しているのか、人間にはわかりません。「制御しきれない部分がある」という前提を受け入れられるかどうか。ここが、従来の開発思考から生成AI時代の思考へ切り替えるための最初のハードルになります。
「もっともらしいウソ」が生まれるメカニズムと、その対策
開発現場で最も頭を悩ませるのが「ハルシネーション(幻覚)」です。もっともらしいウソをついてしまう。これはなぜ起こるのでしょうか?
ハルシネーションが起きる最大の理由は、生成AI(LLM)が思考しているのではなく、「次の単語(トークン)を確率で予測しているだけ」だからです。 AIは文脈的に「次に来る確率が最も高い単語」を選んでつなげているに過ぎません。
例えば、「日本の首都は?」と聞かれたら、「東京」という単語が続く確率が高いからそう答える。 問題なのは、学習データにないことや知らないことに対しても、確率的に繋がりそうな単語を無理やり繋げて、文章を成立させてしまう点です。
「わからない」と言わずに、確率計算だけで文章を作ってしまうんですね。
その通りです。出力層では、次に来る単語の候補が「東京:80%」「大阪:15%」といった確率で算出されます。基本的には確率が高いものを選びますが、設定によってはあえて確率の低いものを選ぶ「ゆらぎ」を持たせることもあります。これが回答の多様性を生む一方で、ウソをつくリスクにもなるわけです。

なるほど。バグではなく、確率モデルである以上「仕様」だということですね。では、開発現場ではハルシネーションはなくせないという前提に立つべきでしょうか?
はい、「ハルシネーションは完全にはなくせない」という前提に立つことがスタートラインです。 もちろん、ChatGPTなどの最新モデルでは、「わからないことはわからない」と答えるような調整が進んでいますが、それでもゼロにはなりません。
ゼロにできないとなると、システム側でどうカバーするかが重要になりますね。
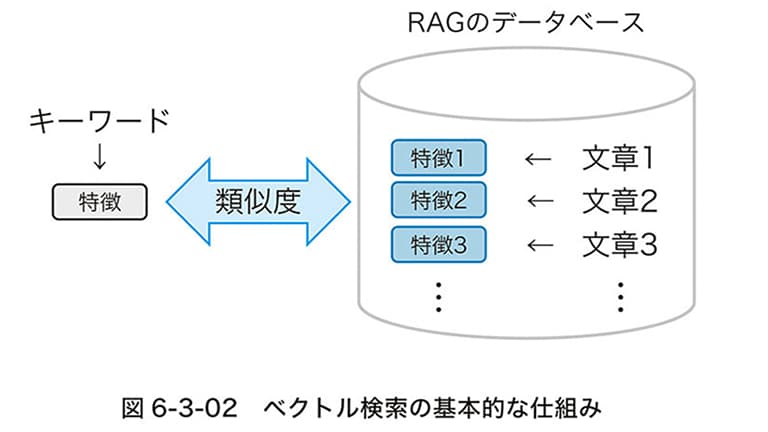
おっしゃる通りです。対策としては、やはりRAG(検索拡張生成)の活用が基本になります。 AIの学習済み知識だけに頼るのではなく、外部の信頼できるデータベースから情報を検索させ、その内容を元に回答を生成させる手法です。
プロンプトエンジニアリングで「嘘をつくな」と指示するだけでは不十分でしょうか?
限界がありますね。「事実に基づかないことは出力しない」という制約も有効ですが、モデルの原理上、確率的な挙動を完全に抑え込むことは難しい。 エンジニアとして「モデルの内部構造(確率的生成)」を理解していれば、「これはプロンプトで直せる問題なのか、それともモデルの原理的に不可能なのか」の切り分けが早くなります。
無駄なプロンプト調整に時間を費やすより、RAGを導入したり、人間がチェックするフローをシステムに組み込んだりと、アーキテクチャレベルでの解決策に頭を切り替えられる。これが仕組みを知る最大のメリットです。
LLMの仕組みの理解が、AIアプリ・エージェント開発にどう活きるか
仕組みの理解がトラブルシューティングの質を高めるということですね。他にも、LLMの内部構造を知っていることで、開発実務において有利になる点はありますか?
「コスト管理」と「レスポンス速度」の最適化において、圧倒的に有利になります。 LLMのAPI利用料は、基本的に「トークン単位」の従量課金です。トークンとは、AIが言葉を処理する際の最小単位のこと。日本語だとひらがな1文字が1トークンになることもあれば、漢字1文字が複数のトークンになることもあります。
最近はコンテキストウィンドウ(入力可能なトークン数)が大きくなりましたが、その分コストもかさみやすくなっています。
何も考えずにすべての会話履歴を送信し続けて、気づかないうちに莫大なコストが発生してしまうケースはよくあります。 仕組みを知っていれば、「過去の履歴を要約してプロンプトに含める」といった工夫でトークン数を節約できます。
また、「コンテキストウィンドウの限界」=「記憶の限界」であることも理解しておく必要があります。AIが前の会話を忘れるのは、単にデータ量の限界を超えて押し出されただけです。 「AIが忘れた!使えない!」と嘆く前に、「AIが記憶を保持できる仕組み」に合わせてシステムを設計してあげるのが、エンジニアの腕の見せ所ですね。

最近は「AIエージェント」の開発も盛んですが、ここでも仕組みの理解は重要でしょうか?
もちろんです。AIエージェント開発では、LLMはあくまで「言葉(テキスト)しか出力できない」という大原則を忘れてはいけません。 例えば「ホテルを予約して」と頼んでも、LLM自体が予約システムにアクセスしてボタンを押してくれるわけではありません。LLMができるのは、「予約に必要な情報を整理して、APIを叩くためのJSONデータを生成する」ところまでです。
実行するのは、あくまでLLMの外側にあるプログラムなんですね。
そうです。AIエージェントを作る際、「どこまでがLLMの仕事(思考・判断)」で、「どこからがプログラムの仕事(実行)」なのか。この境界線を正しく引けるかどうかが、開発の成否を分けます。
LLMの入出力の仕組み(テキストを入れて、確率で選ばれたテキストが出るだけ)を理解していれば、実装すべき機能の全体像が自然とイメージできるはずです。
非技術者にも伝わる、生成AIの能力と限界の上手な説明方法
中級以上のエンジニア、特にPMやPLの立場だと、上司やクライアントに対して「なぜAIは間違えるのか」「なぜこれができないのか」を説明する責任が発生します。非技術者の方に腹落ちしてもらうための、良い説明のアプローチはありますか?
私がよく使うのは、「受験勉強」と「問題集」の例えです。 AIの事前学習は、受験生が問題集を解いて勉強するのと同じです。問題集(学習データ)にある問題や、それに似た応用問題なら解けますが、一度も見たことがない問題や、教科書に載っていない最新の時事問題は解けません。
確かに「ものすごく勉強ができる優等生だけど、2023年までの教科書しか読んでいないんです」と言えば、最新ニュースに答えられない理由も伝わりますね。
もう一つ、ハルシネーションの説明には「ツアーガイド」の例えも有効です。 ガイドブック(学習データ)の内容は完璧に暗記しているツアーガイドさんがいるとします。でも、そのガイドブックが古かったり間違っていたりしたら、ガイドさんは悪気なく、自信満々に間違った案内をしますよね。
また、お客さんからガイドブックに載っていない場所について聞かれたとき、優秀なガイドさんほど「わかりません」とは言いたくない。「確かあっちの方だったかな…」と、うろ覚えの知識や推測で、もっともらしい案内をしてしまうことがあります。
それがハルシネーションだと。「悪気はないけど、サービス精神で適当なことを言ってしまう」という人間臭い感じで伝えると、クライアントも許容しやすくなりそうです。
また、「入力(プロンプト)」と「出力(生成物)」、そしてその間にある「確率的な計算」。この3つの要素を図に書いて説明するだけでも、だいぶ伝わり方が変わります。 エンジニア自身がこの「計算のプロセス」を具体的にイメージできているかどうかが、説得力のある説明ができるかどうかの分かれ目になります。
今後のLLMの進化の方向性と、エンジニアがキャッチアップすべき領域
技術の進化は凄まじく、毎日新しいモデルや論文が出てきます。エンジニアとして、これからの進化の方向性をどう見ておけば良いでしょうか?
大きなトレンドとしては、皆さんもご存じの通り「推論(Reasoning)モデル」の台頭です。OpenAIの「o1」などが代表例ですが、これまでのモデルは、入力に対して即座に確率的な回答を返す「直感型(System 1)」でした。
それに対して、推論モデルは回答を出す前に内部で「思考の連鎖(Chain of Thought)」を行い、論理的なステップを踏んでから回答する「熟考型(System 2)」です。
数学的な難問やプログラミングタスクの精度が上がっていますね。今後は用途に合わせて使い分ける必要がありそうです。
「速いけど浅い即答型」と「遅いけど深い熟考型」の使い分けが求められるでしょう。 ただ、情報のキャッチアップについて言えば、正直なところ「基礎理論」以外は無理に追いかけなくてもいい、というのが私の持論です。
新しいモデルや技術が出ても、本当に重要なものなら、いずれ便利なライブラリやフレームワークに組み込まれ、誰もが簡単に使えるようになります。
最新の論文を追いかけるよりも、基礎を固めるべきだと。
「Transformer」や「Attention」といった根幹の技術(基礎理論)は、トレンドに関係なく使われる知識です。ここさえしっかり押さえておけば、新しいツールが出てきても「ああ、あの中身をこう応用したのね」と類推できます。 特に中級以上のエンジニアの方は、マネジメントやアーキテクチャ設計など、やるべきことが山積みだと思いますので。
確かに、日々の業務に追われる中で、次々と出てくる新技術をすべてキャッチアップしようとすれば、パンクしてしまいますね。
だからこそ、枝葉の最新情報に振り回されるのではなく、一度立ち止まって「なぜ動くのか」という幹の部分を理解することに時間を使ってほしいですね。 AIは魔法ではありません。計算と確率の産物です。 その「裏側」さえ理解してしまえば、AIは皆さんの強力な武器になります。ぜひ、ブラックボックスを恐れずに、その中身を覗いてみてください。
ライター
