
 (画像提供フューチャー株式会社)
(画像提供フューチャー株式会社)フューチャーは9月2日、生成AIのソフトウェア開発で活用できる大規模な日本語インストラクションチューニング(Instruction-Tuning)データを無償公開した。
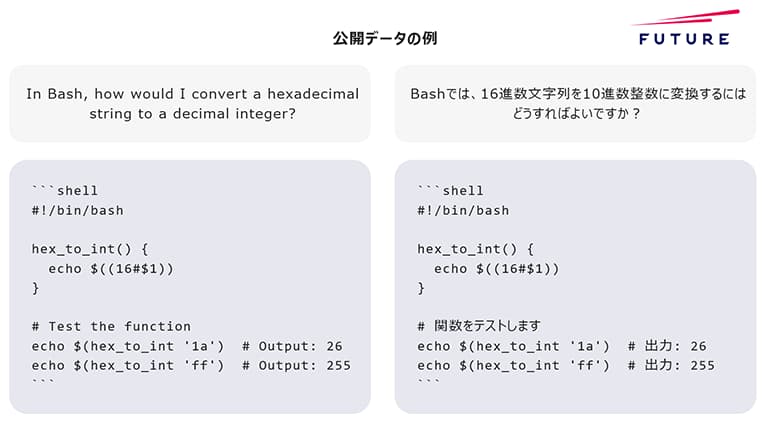
インストラクションチューニングデータは、LLM(大規模言語モデル)のファインチューニング手法の1つで指示(Instruction)と回答のデータセットを学習することで精度を上げるもの。通常、こうしたデータ構築には多額のコストがかかるため、一般公開されている学習用データセットは少なく、日本語に特化したソフトウェアに関するインストラクションチューニングデータの数も限られていたという。
今回公開したのは、シングルターンの日本語530万件、英語610万件、マルチターンの英語85万件のデータセットで、日本語インストラクションチューニングデータでは世界最大規模になるという。LLM(大規模言語モデル)と日本語によるソフトウェア開発領域の研究に活用できる。
フューチャーは、2024年10月に経済産業省とNEDO(国立研究開発法人 新エネルギー・産業技術総合開発機構)が実施する国内生成AIの開発力強化プロジェクト「GENIAC(Generative AI Accelerator Challenge)」に採択され「日本語とソフトウェア開発に特化した基盤モデル」の研究開発を行ってきた。
今回公開したインストラクションチューニングデータは、このプロジェクトの研究過程においてベンチマークとしたLLMをもとに自動生成したものとなる。
また、フューチャーによると、今回のインストラクションチューニングデータを活用して、GENIACのプロジェクトで開発した「Llama 3.1 Future Code Ja」は、様々なプログラミング言語において比較対象となるベースモデルに対し、高い生成能力を実現し、特に日本語の指示によるソースコード補完能力に優れていることも確認したという。

世界最大規模のソフトウェア開発に関する日本語インストラクションチューニングデータを公開することで、日本語のソフトウェア開発の研究と発展に貢献するとしている。
【参考】:フューチャー、ソフトウェア開発に関する世界最大規模の日本語インストラクションチューニングデータを公開 | フューチャー株式会社のプレスリリース
ライター