
 左から酒井氏、白幡氏、梁氏(写真撮影:株式会社ブリッジ)
左から酒井氏、白幡氏、梁氏(写真撮影:株式会社ブリッジ)この記事でわかること
-
大規模言語モデル(LLM)「Takane(高嶺:タカネ)」はスーパーコンピュータ「富岳」を活用した先行研究の知見を基に開発された。
-
「Takane」は、「日本語精度No.1」を掲げて、LLMの正しい日本語表現の課題に正面から取り組んでいる
-
企業にとって重要なデータを高い精度で扱えるだけでなく、安全性と秘匿性にも優れている
OpenAIのChatGPTやGoogleのGeminiのような、大規模言語モデル(LLM)を中核にした生成AIが話題をさらっています。しかし私たちのビジネス環境では、特に日本の商習慣や言語の壁、そして企業におけるデータの秘匿性を考えた時に、これら話題の生成AIが便利で役立つソリューションになるとは限りません。
現在、日本を代表するテクノロジー企業のひとつである富士通が、エンタープライズ向けの大規模言語モデル(LLM)「Takane(高嶺:タカネ)」を提供しています。先行してスーパーコンピュータ「富岳」上で大規模言語モデル「Fugaku-LLM」を開発し、そこで培われた技術と知見をTakaneの開発に活用。日本語理解の精度が高く、業務利用を前提にした高いセキュリティ性能を備えています。さらに、今後はその高いパフォーマンスを維持しながら、世界最高水準の軽量化・効率化を同時に達成しようとしています。
今回はIT・テクノロジーが専門のジャーナリスト・山本敦氏が富士通本店を訪ね、Takaneを担当するキーパーソンである白幡晃一氏、酒井彬氏、梁俊(リョウ シュン)氏のお三方を直撃。各氏が日ごろの仕事と向き合いながら、どのように最先端のテクノロジーを切り拓いてきたのか、開発の舞台裏についてお聞きしました。
白幡晃一(博士 [理学])
富士通株式会社 富士通研究所 人工知能研究所 生成AI コアプロジェクト シニアプロジェクトディレクター。東京工業大学 数理・計算科学専攻 博士課程修了。大学時代の研究テーマはGPU搭載スーパーコンピュータ上でのビッグデータ処理高速化。 富士通での研究分野はスーパーコンピュータ「富岳」上での大規模深層学習高速化、高性能な大規模言語モデルの開発、材料開発(マテリアルズインフォマティクス)・構造/流体設計領域でのシミュレーション高速化、など。パーパスは「世界最先端のコンピューティングとAI技術の研究開発を通じて社会課題の解決を加速する」。
酒井彬(博士 [工学])
富士通株式会社 人工知能研究所 生成AI コアプロジェクト シニアリサーチマネージャー。京都大修士課程修了。専門分野は、量子化、超音波AI応用。 主な経験プロジェクトは、大規模言語モデル量子化(チームリーダー)、マグロ超音波AI(プロジェクト主宰、東海大共同)、胎児心臓超音波AI(理研AIP共同、医科歯科大博士)、脳科学と連携した深層学習の基礎研究(MIT共同)、流体シミュレーションAI・核融合プラズマシミュレーション。
梁俊(LIANG JUN [リョウ・シュン])
富士通株式会社 人工知能研究所 領域特化AI コアプロジェクト。中国湖南省出身。富士通では、比較コーパスの構築(自然言語処理)、アイデンティティ決定のための辞書の構築(同)、言語モデルのドメイン適応(同)、マルチターゲット・マルチカメラ追跡(コンピュータビジョン) などの開発・研究に携わってきた。2023年より大規模言語モデル(LLM、Takane含む) に関連する研究に従事。具体的には、プロンプトエンジニアリング、 LLM評価 、 特定ドメインにおける知識グラフを活用した情報検索と生成(KG-RAG、Knowledge Graph-Enhanced Retrieval-Augmented Generation)の開発・研究を行っている。
目次
富士通研究所が開発する日本語大規模言語モデル「Takane」
現在、生成AIの活用は急速に進んでいますが、その多くは「文章の要約」や「メールの作成」といった個人の業務効率化に留まっているのが現状ではないでしょうか。富士通がTakaneで目指しているのは、さらにその先にまで踏み込んだ「生成AIによる組織・企業活動の革新」です。
富士通の戦略ではAI活用のフェーズを「個人業務の効率化」から「組織業務の自動化」、そして「経営戦略への活用」へと段階的に引き上げることを想定しています。ただ便利なツールとして導入するだけでなく、AIが企業のビジネスモデルを変革するために欠かせないパートナーになる未来を描いています。
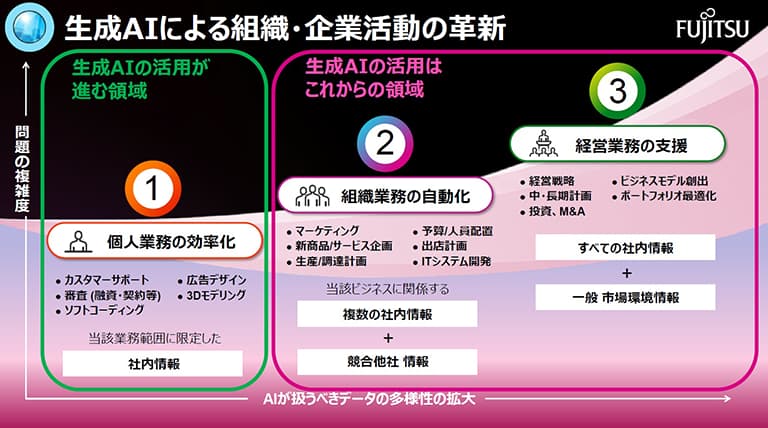
Takaneの開発プロジェクトの中核メンバーである白幡晃一氏は、同社のビジョンを次のように語ります。
「当社としてはクライアントのデジタルトランスフォーメーション(DX)をより強力に押し進めることを事業の目標に掲げています。個人にとどまらないよう、様々な業種の組織業務、調達から設計、製造、販売といったサプライチェーン全体に、生成AIテクノロジーによる革新をもたらしたいと考えています」

では、富士通が目指すAI革新の中核を担うTakaneとは、具体的にどのようなLLMなのでしょうか。
Takaneは、カナダのAIスタートアップであるCohere(コヒア)社と富士通によるパートナーシップのもと開発された、企業の業務向けに最適化したLLMです。最大の特徴は汎用のLLMとは異なり、企業にとって重要なデータを高い精度で扱えるだけでなく、安全性と秘匿性にも優れているところにあります。

汎用的なAIが参照するデータの多くはインターネットを参照しています。ところが一方、企業にとって競争力の源泉となる情報は、社内のクローズドな環境に資産として蓄積されているものです。白幡氏は次のように指摘します。
「例えばChatGPTはネット上のさまざまなデータを参照していますが、企業にとって本当に価値のある情報はインターネットには存在しないことも多いのです。社内に蓄積された情報資産をデータ化し、生成AIと組み合わせて活用できる体制をつくることが、今後も成長を続けるための鍵になります」
また、企業によっては外部からアクセスさせたくないデータも存在するため、社内に構築したオンプレミス環境やクローズドなネットワーク上でAIを運用することが、最も適した選択肢となる場合もあります。
さらに、RAG(Retrieval-Augmented Generation:検索拡張生成)とファインチューニングの技術を組み合わせることで企業独自のナレッジを取り込み、業務に特化した回答を正確に生成できるようにカスタマイゼーションを図ることもできます。

日本語理解と論理推論に強み
AIの技術をベースとしたチャットサービスの中には、日本語特有のニュアンスが通じなかったり、表現が不自然になったりするものがあります。Takaneは「日本語精度No.1」を掲げて、LLMの正しい日本語表現の課題に正面から取り組んでいます。具体的には日本語強化のための追加学習とファインチューニングを行ったことで、日本語言語理解のベンチマークであるJGLUEでは、海外製のLLMを大きく引き離す高スコアを獲得しています。
日本語は、主語の省略や敬語の使い分け、漢字・ひらがな・カタカナの混在など、とても複雑な文章構造を持っています。この難題に対し、開発チームはスーパーコンピュータ「富岳」を活用した先行研究(Fugaku-LLM)で培った知見を基に、大規模な学習データの構築とモデルの並列化・高速化の技術をTakane開発に応用しました。

評価とデータセット構築を担当する梁氏は、日本語性能向上のプロセスをこう振り返ります。
「日本語のデータセットを作る際には、いったん英語のデータセットを作る手順をベースとしつつ、日本語特有の部分、つまり本質が近いところと異なるところを比べながら最適化を図っています。私のチームの中では、日本語ネイティブのスピーカーと議論を何度も重ねながら精度向上を追求しています」

例えば企業の決算短信のように、専門的で複雑な日本語によるテキストの解析もTakaneは得意としています。ひとつの長い文章の中で主語と述語が離れていても、文脈からそれぞれの関係を正確につかむことができます。海外のLLMに比べると、その差は明快に浮かび上がります。

そしてTakaneのもう1つの強みは、与えられた情報をもとに筋道を立てて結論を導く論理推論です。モデルが文脈を理解し、関係性を整理しながら最適な答えを導くための総合的な能力を指します。
例えば会社の従業員が「お正月とお盆では、どちらが長期間の休暇ですか?」と質問した場合、Takaneは社内の就業規則を読み取り、そこに記載された「お正月は1月1日〜3日」「お盆は8月13日〜16日」といった休暇に関する情報を文脈として理解します。そのうえで各期間の日数を計算し、「お正月は3日間、お盆は4日間なので、お盆の方が長い」という結論を導きます。リクエストに応じて、文書内の情報を関係性のある知識として整理しながら推論できる点もTakaneの特徴です。

Takaneは日本語の単語理解が優れているだけでなく、日本語による文脈を把握して論理推論を行います。必要に応じて社内規定のデータから日付や検索条件の関係性を整理した内部データを生成し、それを参照しながら整合性のある回答を導き出します。このような根拠を踏まえた推論処理が、企業内部のデータを正確に扱い、業務に活かすためにも重要になります。
エッジで動くAIモデルの条件とは?Takaneが目指す軽量化と個別最適化
「AIの進化」と聞くと、そのモデルが大きくなり、計算規模がさらに増えていく「スケールアップ」をイメージすると思います。しかし現在、富士通が注力しているのはその逆を行く「コンパクト化」と「省電力化」です。
AI研究のトレンドは「領域特化/Industrialization」や「個別化/Individualization」の方向にシフトしつつあります。巨大な汎用モデルをクラウドで動かすのではなく、必要な機能に絞った軽量なモデルを、エッジ側のデバイス(コンシューマ向けのPCや業務用ワークステーション)でオフラインのまま動かすという考え方です。

AIの軽量化と省電力を目指す量子化プロジェクトのチームリーダーである酒井氏は、同社の狙いを次のように説明しています。
「例えば個人の従業員の方が使うコンピュータの上で、より軽量化したTakaneのモデルが走るようになれば、『ひとり・1・Takane』のような環境も構築できます。現在の規模が大きなTakaneでも、技術的には同じような環境をつくることもできるのですが、導入コストやマシンの設置スペースの負担などがかかります。モデルを効率よく圧縮することで、生まれるメリットは大きいと考えています」

私たちがパソコンで何気なくChatGPTのような大規模言語モデルを利用すると、その裏側ではクラウド上のGPUやAIアクセラレータが短時間で大量の計算処理を行います。これらの計算資源は1人のユーザーが独占するのではなく、多数のユーザーが共有しながら効率よくスケジュールされて動作します。そのため推論自体の電力消費は比較的短時間ですが、世界規模で利用されていることから、全体としては大きな電力需要を生んでいます。
企業活動において環境負荷(消費電力)の低減は無視できない課題です。また、各社員のPCでAIが動作すれば通信の遅延もなく円滑に仕事が進められるだけでなく、セキュリティ上のリスクも低減できます。
富士通独自の量子化技術「QEP」の特徴
LLMを軽量化するための鍵となる技術が「量子化」です。これは、AIのパラメータ(重み)を表現するデータ量を、標準的な16ビットや32ビットから、より少ないビット数に「減らす=圧縮する」ための技術です。
ところが一方ではビット数を減らすほどに、AIの精度は低下します。特に「1ビット」まで量子化を進めてしまうと、従来の手法では処理精度が崩れて使い物にならない現状があります。
そこで富士通が開発したのが、独自の「QEP(Quantization Error Propagation:量子化誤差伝播法)」です。
その仕組みを概略すると、従来の技術ではニューラルネットワークの層ごとに発生した「ズレ(誤差)」が積み重なり、最終的に大きな破綻を招いていました。対してQEPは、ある層で発生した誤差を次の層へ、さらに次の層へと受け継ぐことで、ネットワーク全体として整合性が取れるように調整します。
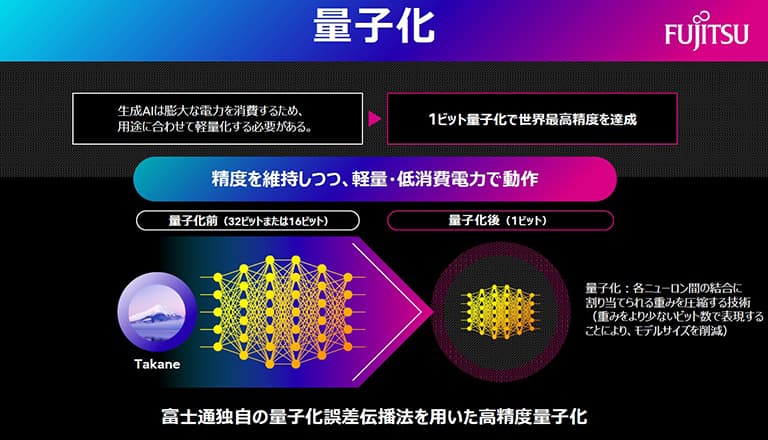
酒井氏はこの仕組みを、会社のチームワークに例えてわかりやすく説明してくれました。
「従来手法だと1人目(=1層目)の人がやったミスを、何も考えずに2人目(=2層目)の担当者が引き継ぎ、さらにミスを加えて3人目(=3層目)以降の担当者に渡してしまうイメージでした。これでは計算全体に狂いが生じてしまいます。QEPを会社のチームワークに例えるのならば、前の人が失敗したところも含めて次の人に渡して、最終的に全体を1本のものさしで把握しながらミスを正そうという手法です」
この技術により、富士通は1ビット量子化において世界最高の精度維持率89%を達成しました。言い替えれば、これはメモリ使用量を最大94%削減しながら、実用的な性能を維持できることを意味しています。ノートPCのような限られたリソースでも、高度なLLMがスムーズに動かせる未来がすぐそこまで来ています。

これからのAIエンジニアには何が求められているのか
最前線で研究開発に取り組む3名に、これからの時代に求められるエンジニアの素養について伺いました。白幡氏は基礎としての数学力の重要性を強調します。
「AIエンジニアリングに必要なものとは何かと聞かれたら、私は数学的な能力だと思います。スーパーコンピュータに関わるLLMのテクノロジーも、基本を突き詰めるとやはり数学の知識にたどり着きます。例えば『量子化』のことは、最初は知らなくても、学ぶことで理解できるようになります。研究開発に関わるエンジニアは、世の中にまだ存在しないものをつくる仕事に携わります。その仕事はどこかのブログを読んで、知識を模倣することで乗り越えられるものではありません。ひたむきな理論と実践の繰り返しになります。その作業を粘り強く打ち込むためにも数学力を鍛えておくことが大切です」

一方、酒井氏は、常に変化するAIトレンドに対する「好奇心」と「フラットな視点」を挙げます。
「ニューラルネットワークにより、人間の脳を模倣するという技術的なアプローチは、今から20〜30年前ごろから研究されています。ではAIテクノロジーが新しいものではないかといえば、私はまったくそうではないと考えます。むしろ、とても新しい技術のトレンドがものすごいスピードで変わるダイナミックな分野です。
初めて世の中に誕生した新しいテクノロジーの中でも、殊にAIに関わるものは軽視されがちになります。酒井氏は「ChatGPTのような大規模言語モデルが出てきた当初、多くの専門家がプロンプトエンジニアリングを軽視していました。ところがそれは、現在のAI研究においてとても大きな部分を占めていると私は考えています」と語ります。
「いまのAIは従来技術の延長線上にあるもの」という捉え方をするのは、研究者として、あるいはこれから先駆者を目指すエンジニアの姿勢としては相応しくないと酒井氏は指摘します。
「むしろ何が変わっていて、何が最先端なのかをフェアな視点で見極めることが重要です。AIの分野ではテクノロジーの流行りや廃りがめまぐるしく変わります。得意とする分野の研究に深く没頭できる能力も大切ですが、広く、様々な話題や知識に視野を広げて、アンテナを伸ばし続けることも大事ということです」

梁氏もまた「日々の積み重ねの大切さ」を語ります。「私はできる限り課題を具体化して、小さな一歩から踏み出すことを心がけています。LLMの研究開発に関わる私の仕事の基本は、言語の本質を正しく把握して、検証に基づいた知識を自分で積み重ねていくことです。手を動かしながら自分自身の糧としていくことが、エンジニアとしての成長に直結していると思っています」

日本のビジネス現場に即した言語理解、企業のセキュリティ要件を満たす設計、そして環境負荷とコストを劇的に下げる量子化技術。これらが組み合わさった、真の意味でエンジニアやビジネスパーソンが安心して使い倒せる、富士通独自の大規模言語モデルが「Takane」なのです。
世界最先端の技術競争の中で、日本独自の強みを発揮する富士通のエンジニアたちの挑戦は大きな刺激と希望を与えてくれます。

ライター
